Building Human-Aligned AI Products with RLHF - A Product Managers Guide
As AI models become more powerful, aligning their behavior with human values is no longer optional -it's a necessity. This guide breaks down how Product Managers can deploy Reinforcement Learning from Human Feedback (RLHF) using Vertex AI. Structure human-in-the-loop pipelines & train reward models.

🎯 "AI doesn't just learn from data - it learns from what we value. Reinforcement Learning from Human Feedback (RLHF) is how we teach AI to be helpful, not just correct."
Why Human-in-the-Loop is a Product Imperative
As AI PMs, we often chase accuracy, throughput, and latency. But when users ask “Why did the model say this?” - performance metrics alone don’t tell the full story.
Modern AI must do more than compute - it must behave. And to shape behavior, we need to inject human values directly into the model learning process. That’s where Reinforcement Learning from Human Feedback (RLHF) becomes a key capability.
Before diving into RLHF, let’s break down its two core components:
⚙️ 1. Understand the Foundations: What PMs Need to Know About RL
Reinforcement Learning is a type of machine learning where agents learn optimal behavior through trial and error, guided by rewards.
| Component | Role in RL |
|---|---|
| Environment | The scenario or task (e.g., conversation, quality inspection) |
| Agent | The model or policy being trained |
| Action | A decision the model takes (e.g., selecting a response) |
| Reward | A signal indicating how good the action was |
| Policy | The model that maps states to actions |
Example: In a chatbot, the RL policy may be rewarded for giving helpful, safe, or humorous replies depending on user ratings.
🙋♂️ 2. Capturing Human Judgment as a Product Signal
While RL is powerful, it's only as good as the reward function- and designing reward functions is hard. That’s why human feedback becomes the most reliable proxy for what’s “good.”
Human feedback can take many forms:
- Ranking model outputs
- Flagging offensive or biased answers
- Providing accept/reject labels
- Annotating corrections or preferences
This forms the foundation for building a Reward Model that approximates what humans value.
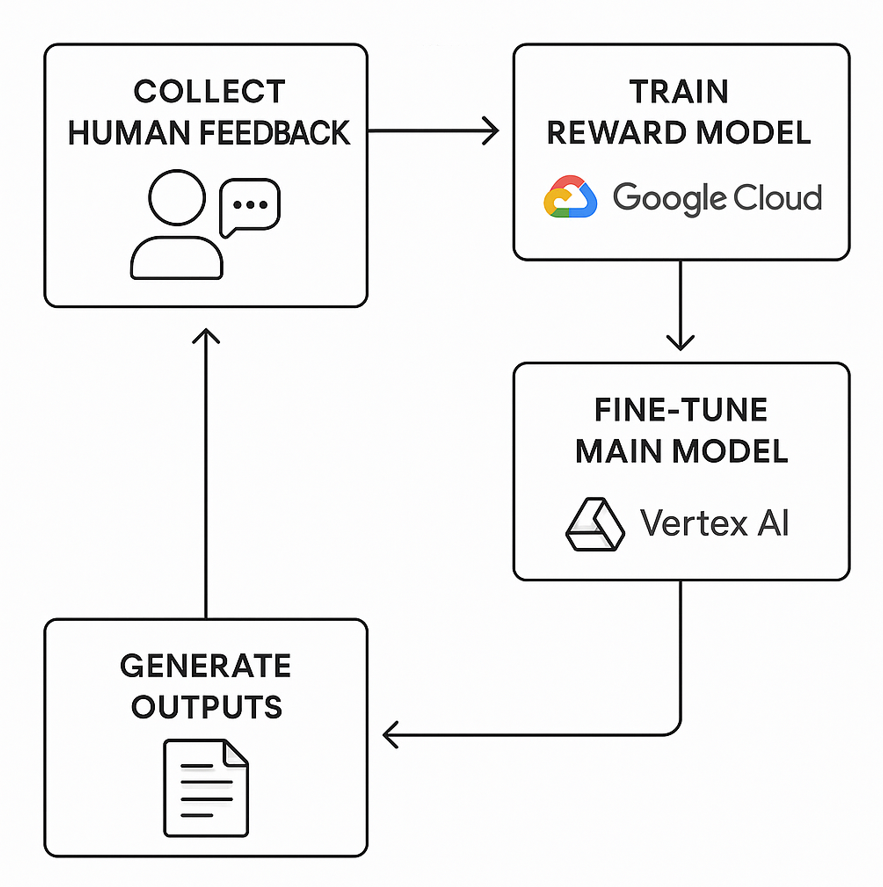
🔄 3. Orchestrating RLHF: The Product Flow
Reinforcement Learning from Human Feedback enhances traditional RL with human-aligned reward modeling:
- Collect Output Samples: Generate model completions for given prompts.
- Human Ranking: Ask humans to rank or rate outputs.
- Train Reward Model: Use this feedback to build a reward model (RM) that mimics human preferences.
- Fine-tune Base Model: Apply RL (e.g., Proximal Policy Optimization) using the RM to optimize for helpfulness, safety, etc.
🧩 Treat the Reward Model like your UX metric engine. You’re aligning model behavior with user delight-not just math.
🛠️ 4. Building the RLHF Stack with Vertex AI
While RLHF isn’t natively abstracted in Vertex AI yet, the platform provides all the building blocks to implement it:
🧾 Feedback Collection
- Use Vertex AI Data Labeling or Ground Truth labeling jobs.
- Automate UI-based human ranking tasks via Workbench Notebooks.
🧠 Reward Model Training
- Train reward models using Vertex AI Custom Jobs with PyTorch or JAX.
- Save checkpoints and deploy using Vertex AI Model Registry.
🔁 Policy Optimization
- Leverage Vertex Pipelines to orchestrate PPO or other RL algorithms.
- Store metadata, artifacts, and evaluation results using ML Metadata Tracking.
📉 Monitoring & Re-evaluation
- Track real-world behavior with Vertex Model Monitoring.
- Detect serving drift and retrigger tuning via pipeline events

🧪 5. RLHF Model Tuning Strategy: From Feedback to Production
| Phase | Goal | Vertex AI Tooling |
|---|---|---|
| Base Model Pre-training | Learn general task distribution | AutoML, Vertex Training Jobs |
| Reward Model Training | Learn human preferences | Custom Training, Model Registry |
| RL Optimization (e.g. PPO) | Align model to feedback signals | Vertex Pipelines, Workbench, OSS RL libs |
| Continuous Evaluation | Monitor behavior & alignment | Model Monitoring, Explainable AI |
💡 Tip: Create separate pipelines for RM tuning and policy tuning to decouple testing and iterations.
🏭 Use Case for PMs: Smart QA in Manufacturing
In a smart manufacturing line, cameras use AI to detect micro-defects. Early models had high recall but were over-triggering stoppages for minor issues.
✔️ Engineers provided binary feedback (“Acceptable” vs. “Defect”) on edge cases.
✔️ Reward model trained using this annotated data.
✔️ Main model was fine-tuned via RLHF using PPO inside Vertex Pipelines.
✔️ Model retraining was automated with feedback loops.
Results:
- 🔽 41% reduction in false positives
- ⏱️ QA downtime cut by 20%
- 🤝 Improved collaboration between line workers and ML ops teams
🧰 Open-Source Alternatives for Early-Stage Product Teams
| Vertex AI Capability | OSS Alternative |
| Data Labeling | Label Studio, Prodigy |
| Custom Training | HuggingFace Transformers + TRL |
| RL Algorithms | PPO (via RLlib, Stable-Baselines3, Acme) |
| Serving & Monitoring | MLflow, FastAPI, Prometheus |
| CI/CD | GitHub Actions + KServe + Argo Workflows |
🚀 Final Word: Product Managers Shape Model Behavior
Reinforcement Learning from Human Feedback isn’t just an ML technique. It’s a product strategy - a way to align AI with real human needs.
With Vertex AI, product teams can:
- Orchestrate feedback pipelines
- Train preference-aligned reward models
- Optimize model behavior for trust, not just precision
And most importantly: keep humans in the loop as stewards of AI quality.
💬 Let’s Discuss:
Are you using RLHF or planning to? What tooling or feedback design has worked for you?
👇 Drop your experience or tag a fellow AI PM diving into model alignment.